本文共 13837 字,大约阅读时间需要 46 分钟。
0 大纲


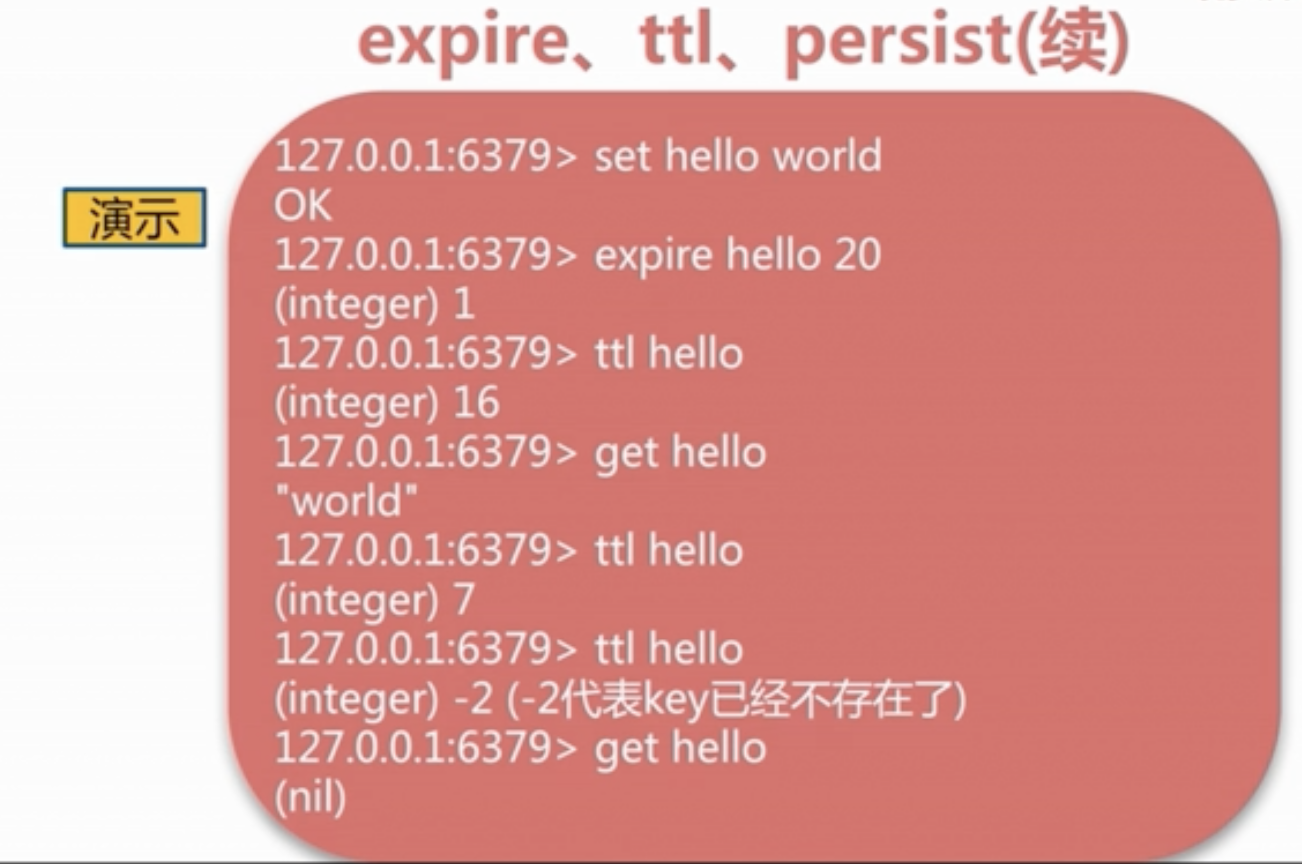
1 通用命令












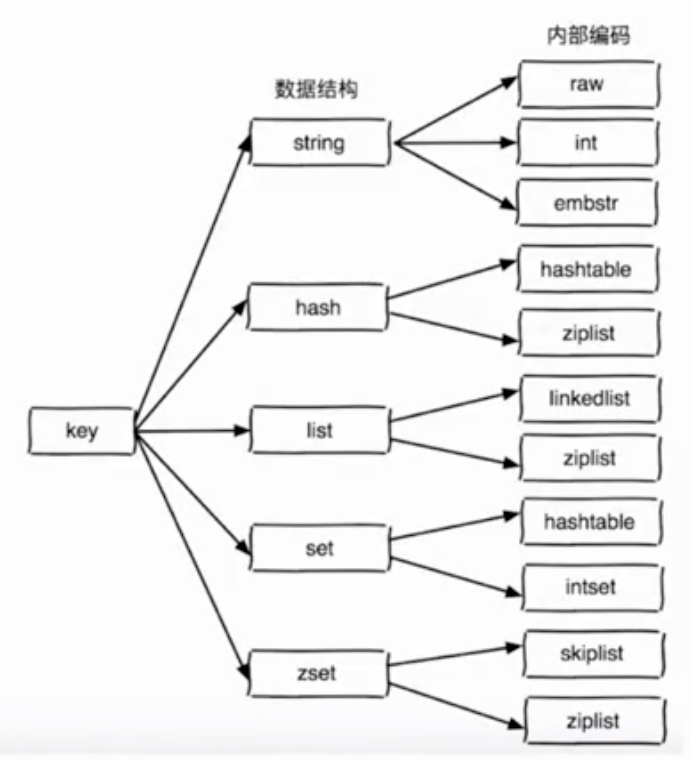
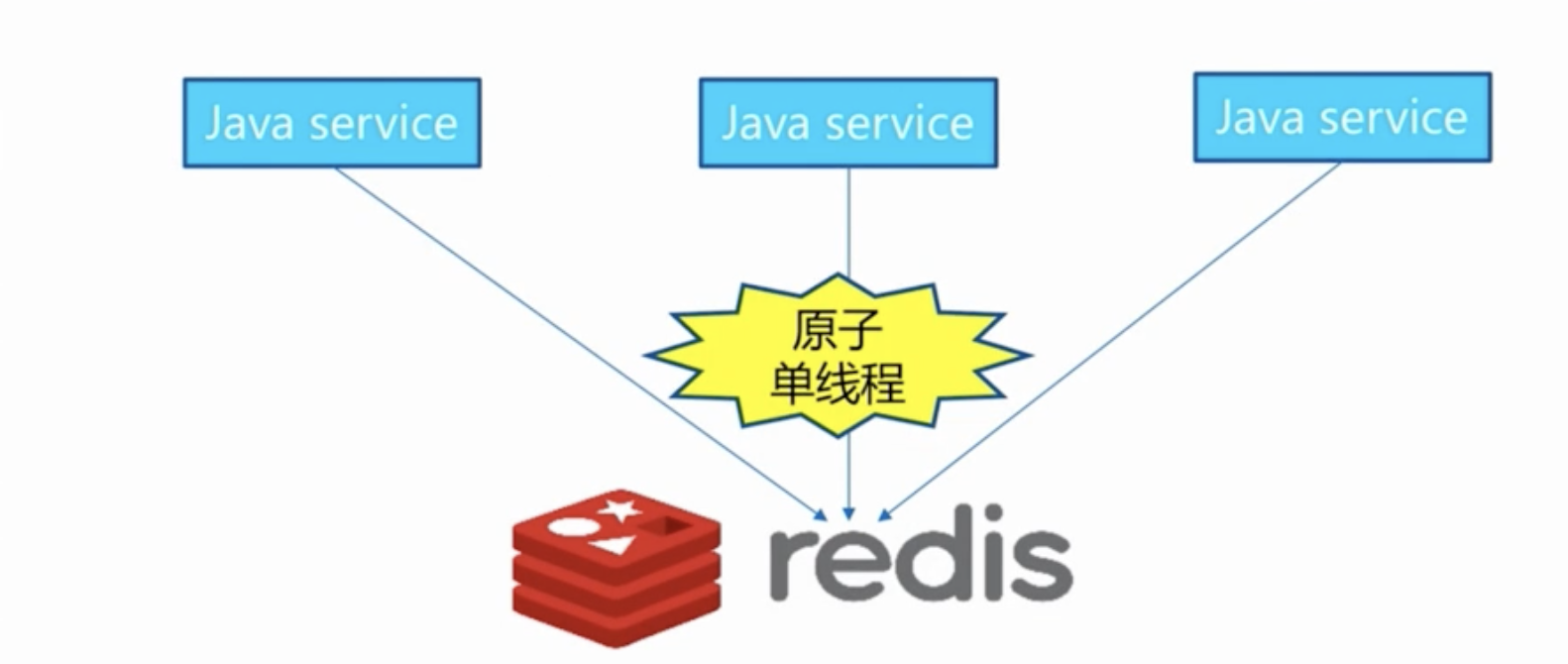
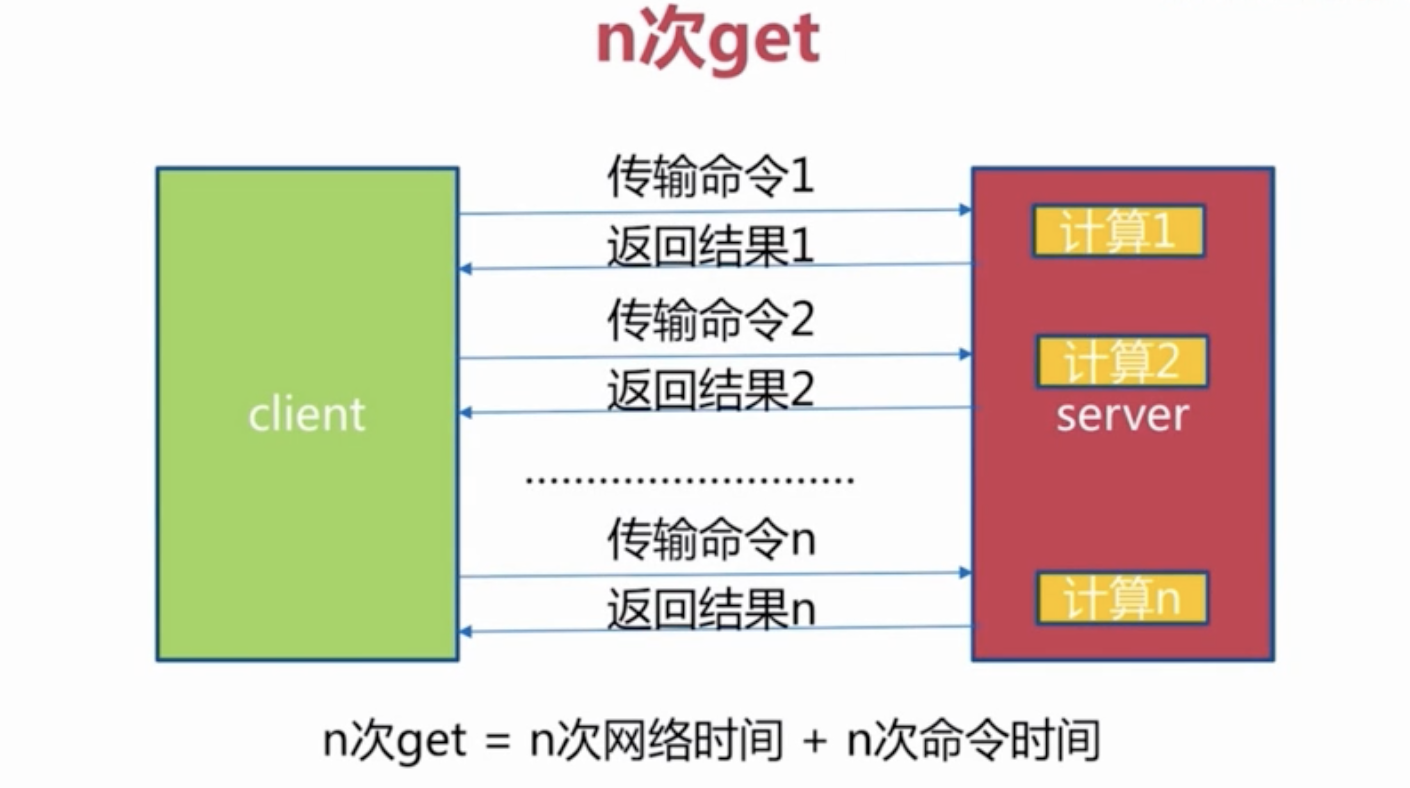
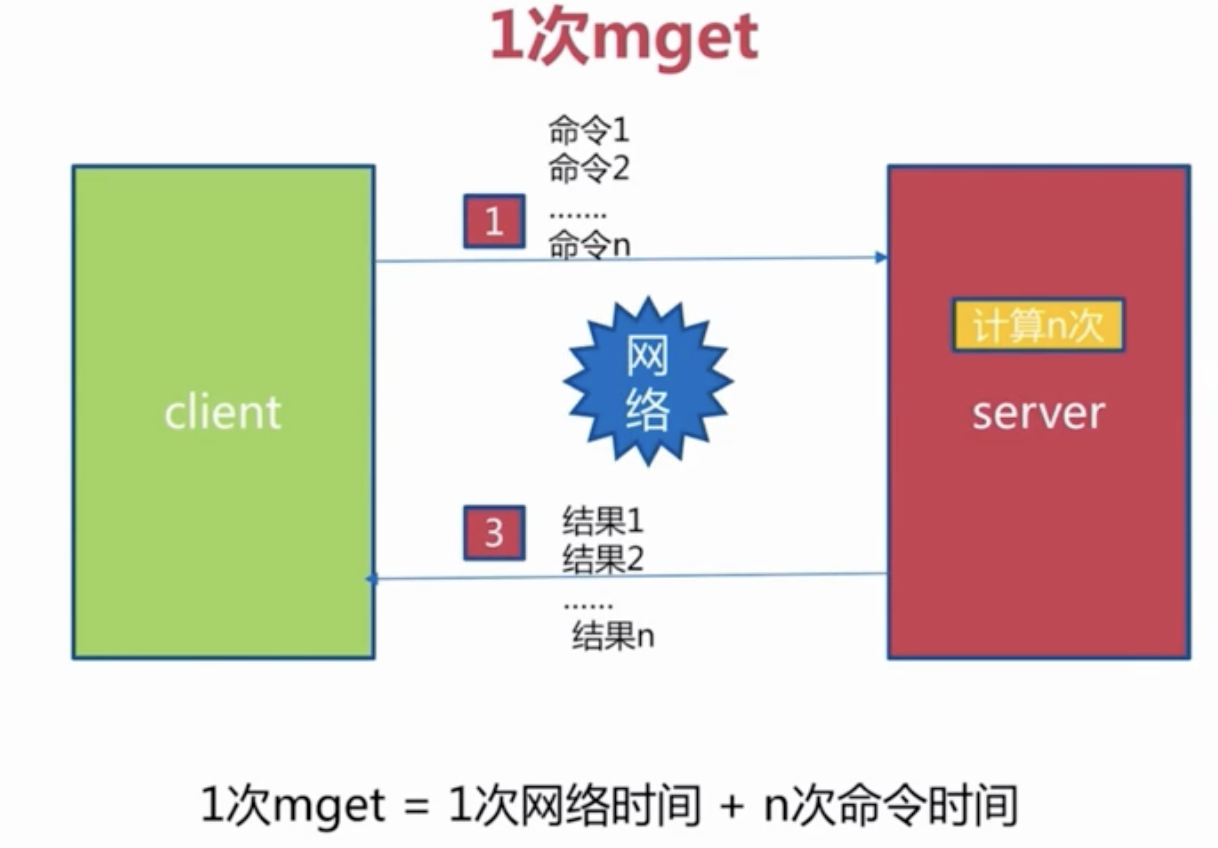
2 数据结构和内部编码
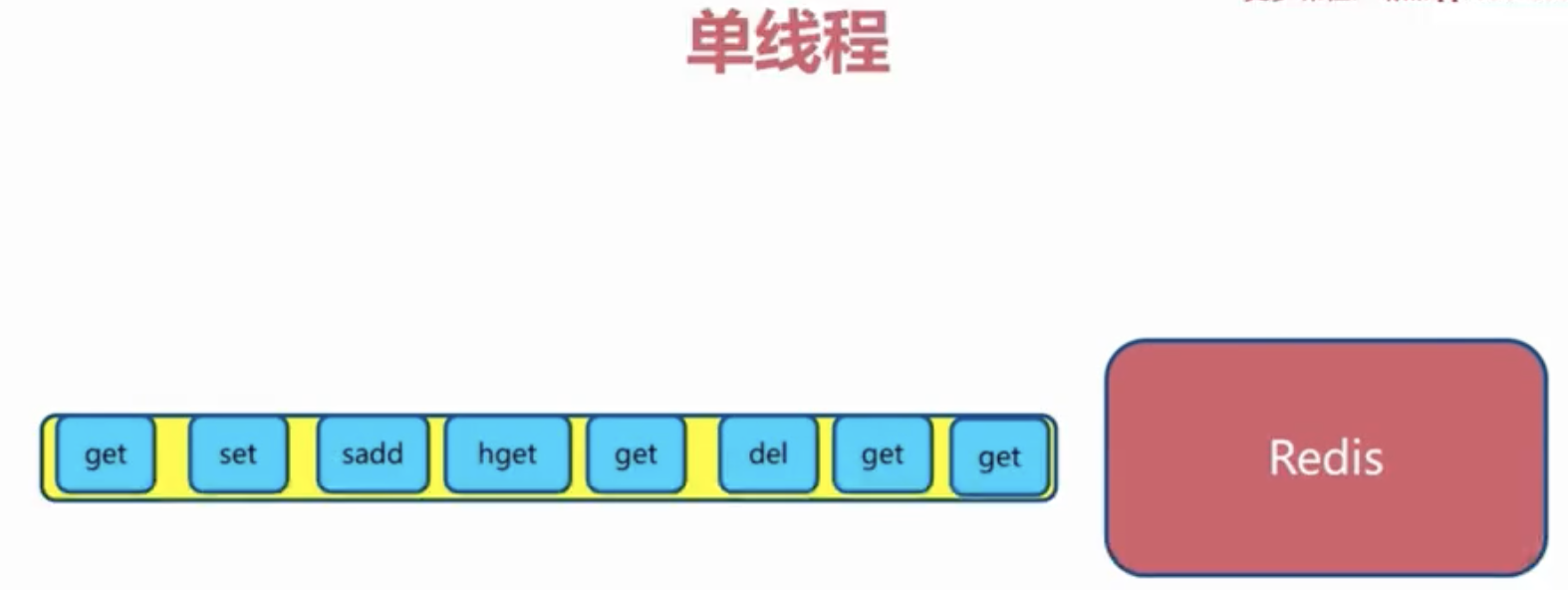
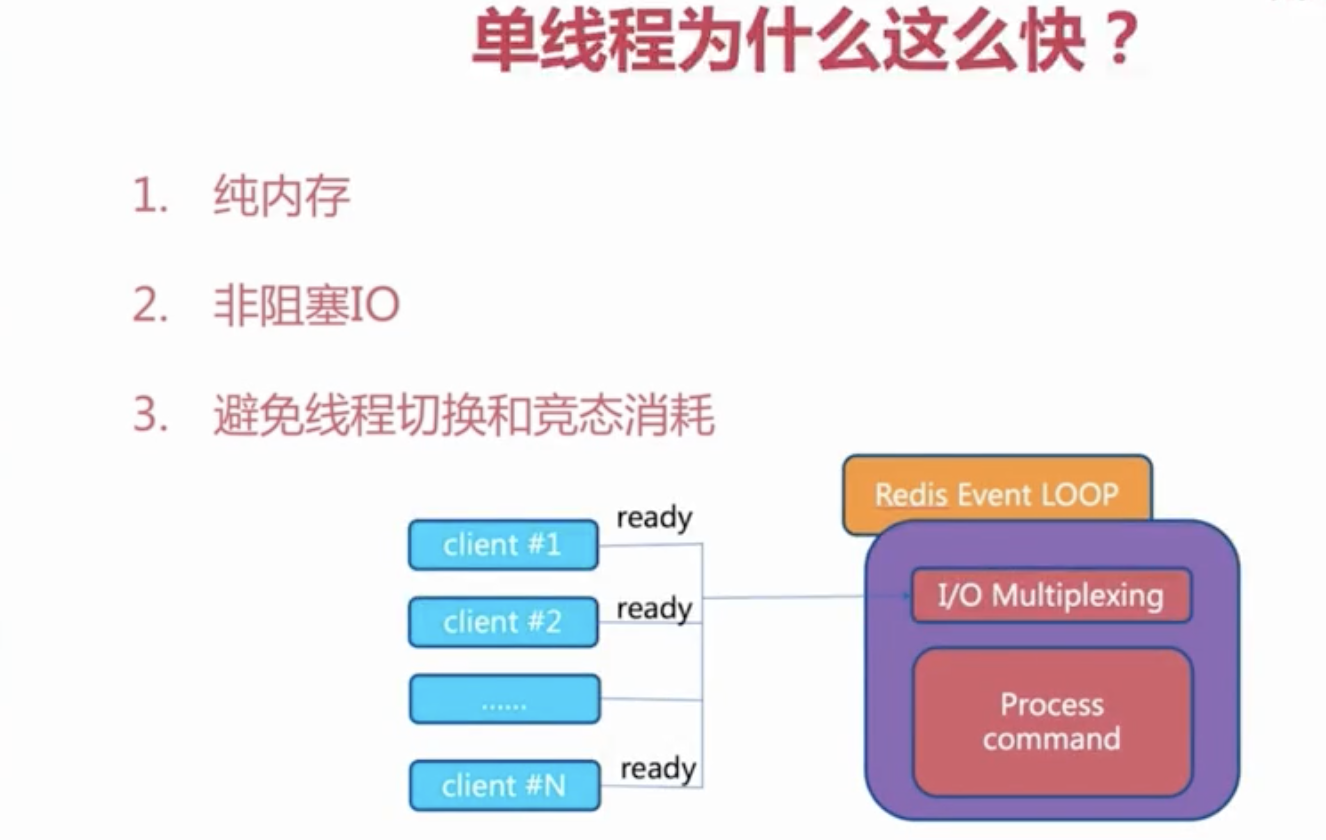
3 单线程

4 字符串(String)

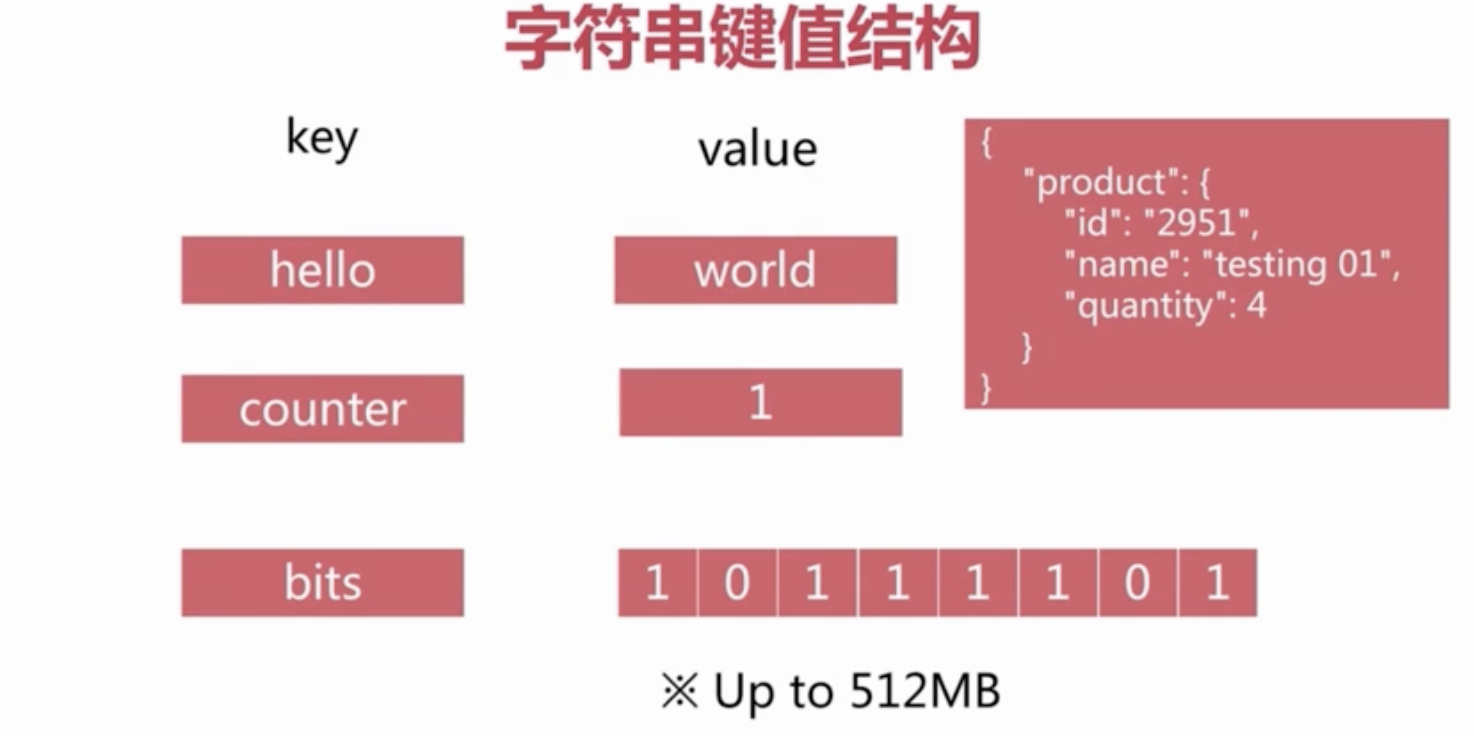













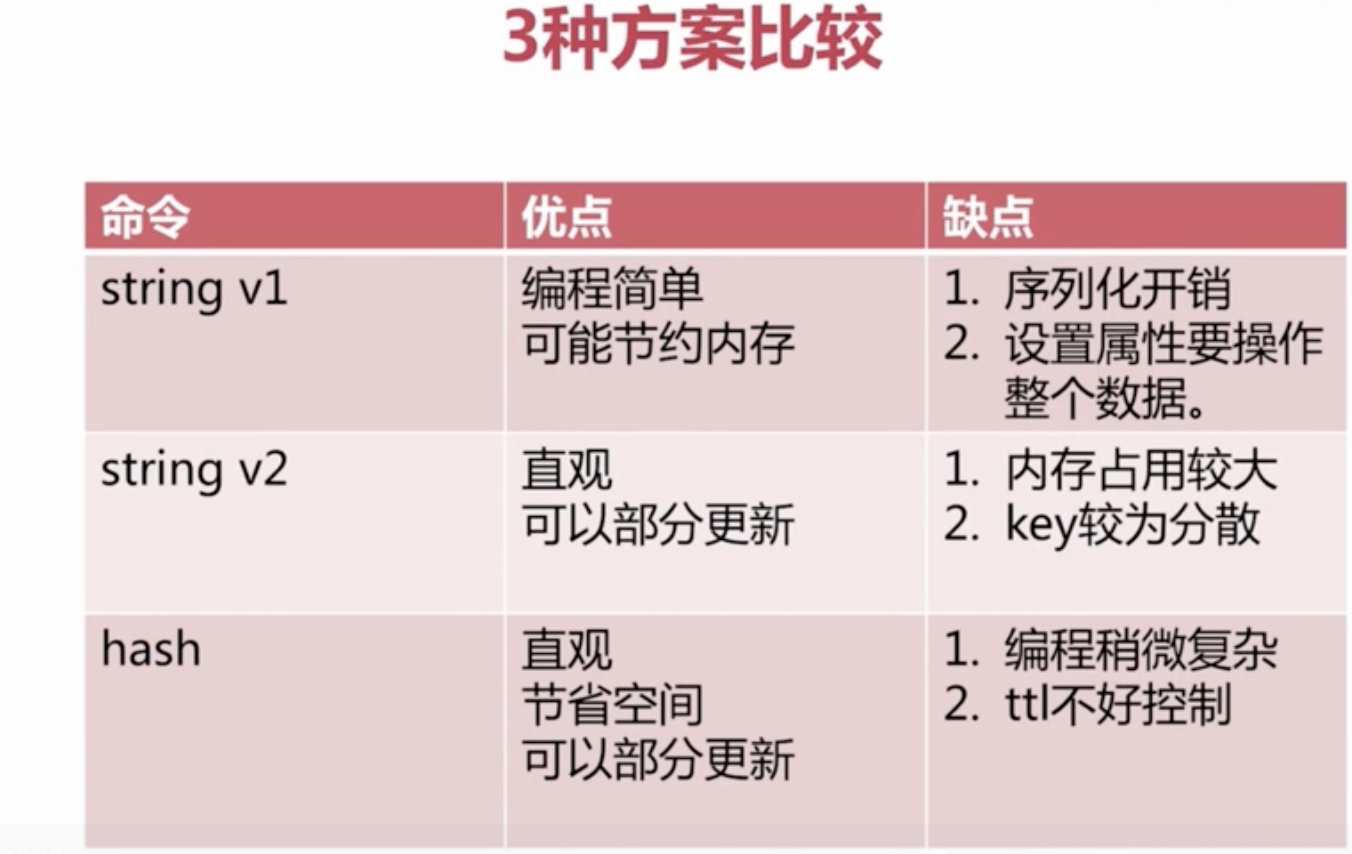
Redis中最基本的类型。
Redis中的String 类型是二进制安全的,也就是说在Redis中String类型可以包含各种数据,比如一张JPEG图片或者是一个序列化的Ruby对象。一个String类型的值最大长度可以是512M。在Redis中String有很多有趣的用法
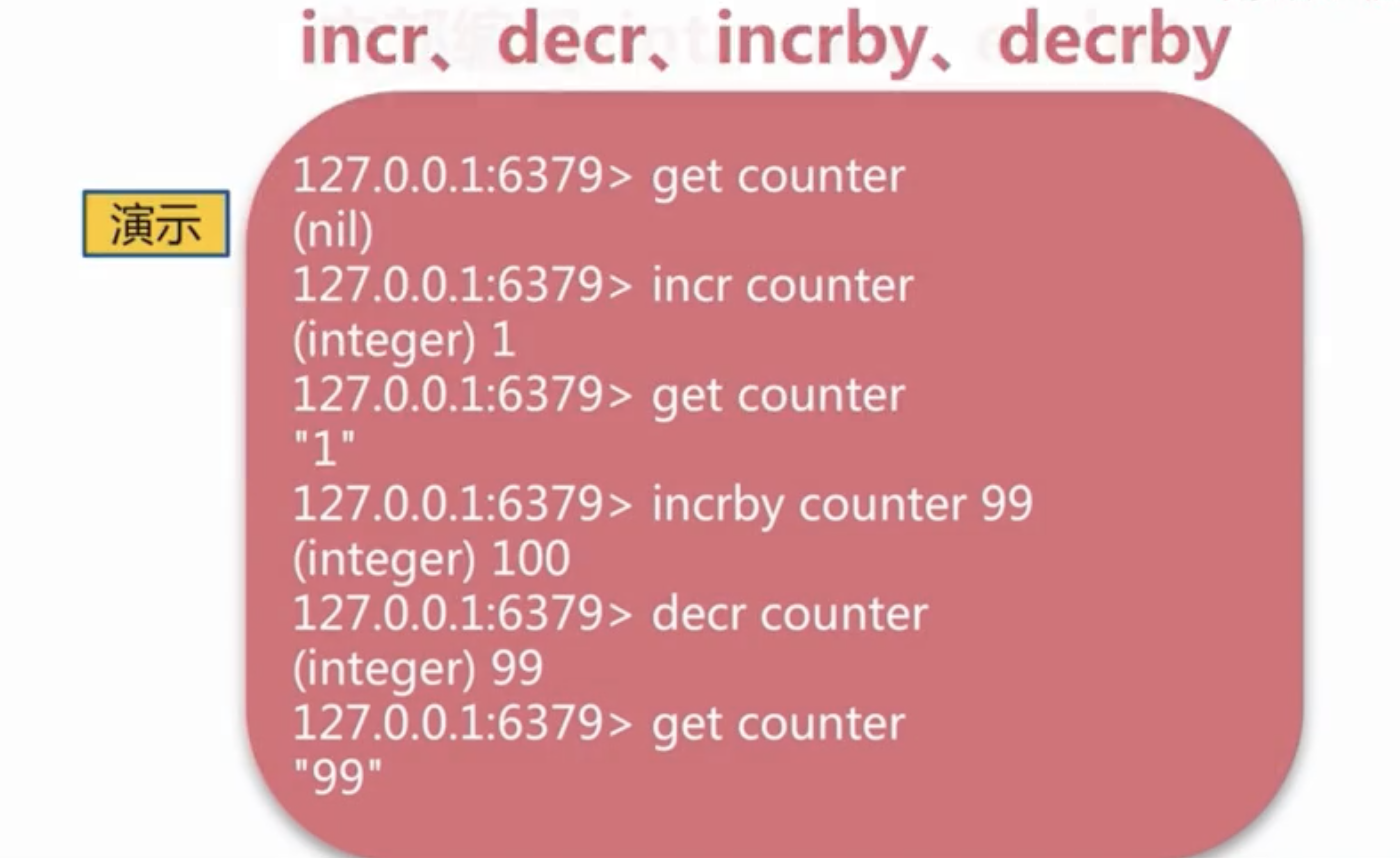
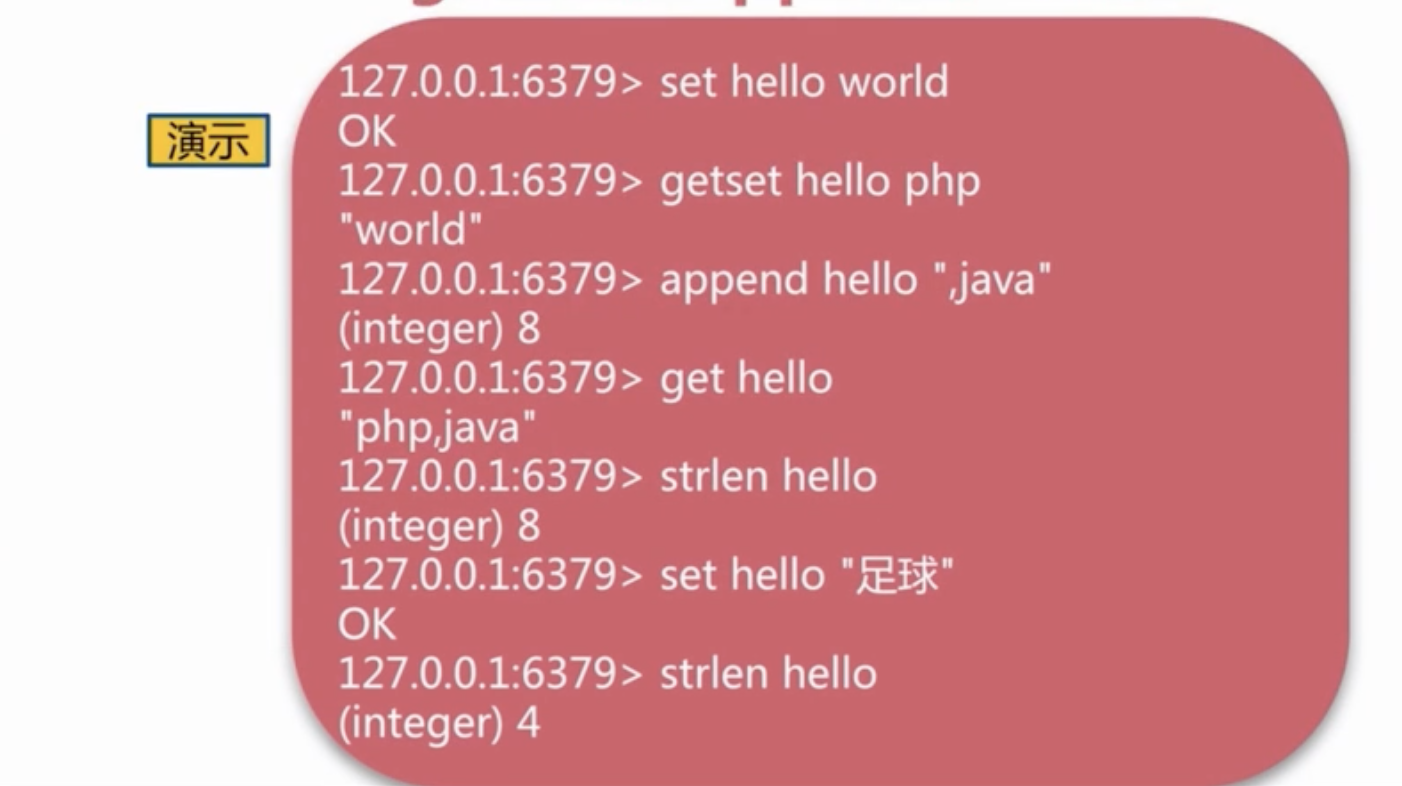
- 把String当做原子计数器,这可以使用INCR家族中的命令来实现:, , 。
- 使用命令来给一个String追加内容。
- 把String当做一个随机访问的向量(Vector),这可以使用和 命令来实现
- 使用 和方法,在一个很小的空间中编码大量的数据,或者创建一个基于Redis的Bloom Filter 算法。
Lists
Redis的列表类型中存储一系列String值,这些String按照插入的顺序排序。Redis的List可以从头部(左侧)加入元素,也可以从尾部(右侧)加入元素。
元素个数和单个元素的长度较小时,采用 ziplist 减少内存占用,否则用linklist 结构
命令是在头部加入一个新元素, 命令是在尾部加入一个新元素。当在一个空的键值(key)上执行这些操作时会创建一个新的列表。类似的,当一个操作清空了一个list时,这个list对应的key会被删除。这非常好理解,因为从命令的名字就可以看出这个命令是做什么操作的。如果使用一个不存在的key调用的话就会使用一个空的list。
一些例子:
LPUSH mylist a # 现在list是 "a"LPUSH mylist b # 现在list是"b","a"RPUSH mylist c # 现在list是 "b","a","c" (注意这次使用的是 RPUSH)
list的最大长度是2^32 – 1个元素(4294967295,一个list中可以有多达40多亿个元素)
从时间复杂度的角度来看,Redis list类型的最大特性是:即使是在list的头端或者尾端做百万次的插入和删除操作,也能保持稳定的很少的时间消耗。在list的两端访问元素是非常快的,但是如果要访问一个很大的list中的中间部分的元素就会比较慢了,时间复杂度是O(N)。
Redis的Lists类型有很多有趣的用法
- 在社交网络中使用List进行时间表建模,使用命令在用户时间线中加入新的元素,然后使用 命令来获得最近加入的元素。
- 可以把 和 命令结合使用来实现定长的列表,列表中只保存最近的N个元素
- 在创建后台运行的工作时,Lists可以作为消息传递原语,例如著名的Ruby库
- 还有很多可以使用lists来做的事,这种数据类型支持很多命令,包括像这样的阻塞命令
Sets
Redis的Sets类型是String的无序集合。增加,删除,测试元素是否存在的时间复杂度都是O(1)(不管集合中有多少元素都是稳定的时间消耗)
Redis Sets的一个重要特性是不允许重复元素。向集合中添加多次相同的元素,集合中只存在一个该元素。在实际应用中,这意味着在添加一个元素前不需要先检查元素是否存在。
关于Redis Sets一个非常有意思的事情是,它们支持多个服务器端命令来从现有集合开始计算集合,所以执行集合的交集,并集,差集都可以很快。
set的最大长度是2^32 – 1个元素(4294967295,一个set中可以有多达40多亿个元素)
Redis Sets有很多有趣的用法
你可以使用Redis Sets来记录唯一的事物,比如,你想知道访问某个博客的IP地址,不要重复的IP,这种情况只需要在每次处理一个请求时简单的使用命令就可以了,可以确信不会插入重复的IP.
Redis Sets 可以很好的表示关系。你可以使用Redis创建一个标签系统,每个标签使用一个Set来表示。然后你可以使用 命令把具有特定标签的所有对象的所有ID放在表示这个标签的Set中。如果你想要知道同时拥有三个不同标签的对象,那么使用命令就好了。
你可以使用 或者 命令从集合中随机的提取元素。
查看获得更多信息,或者阅读一章
Hashes/ Maps

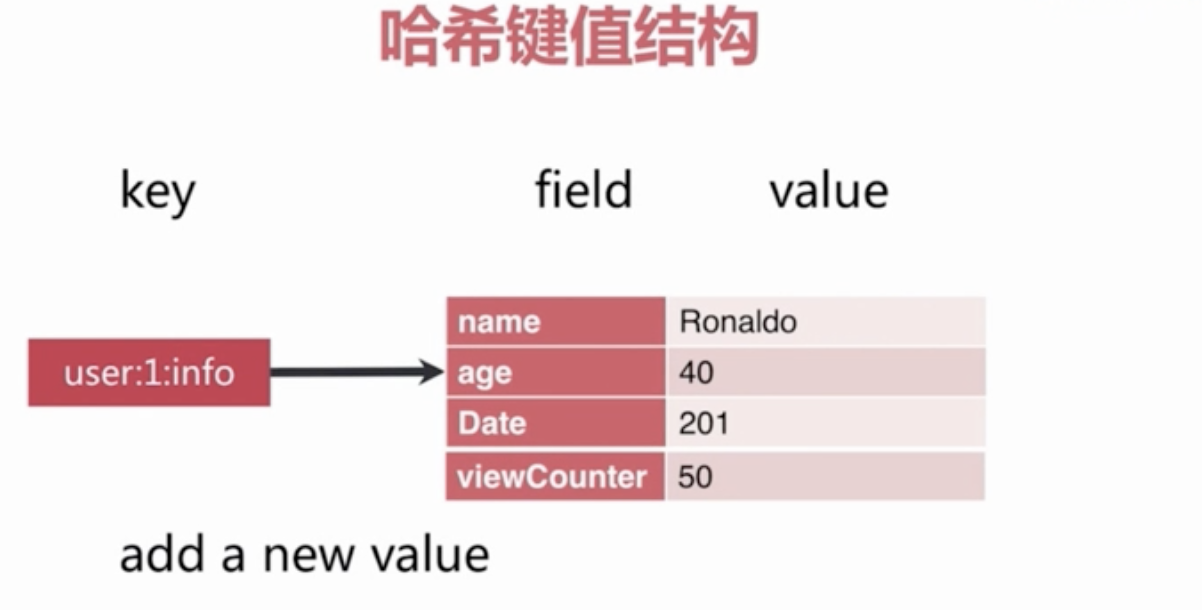





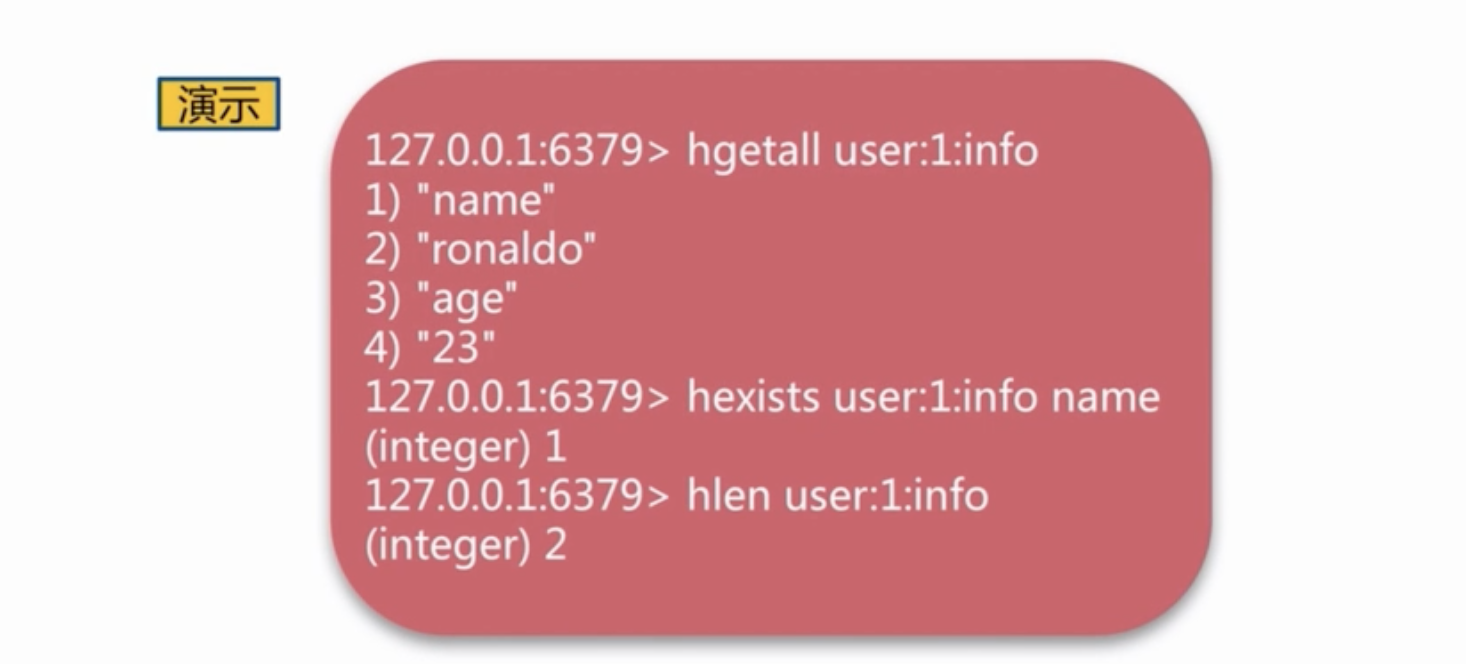











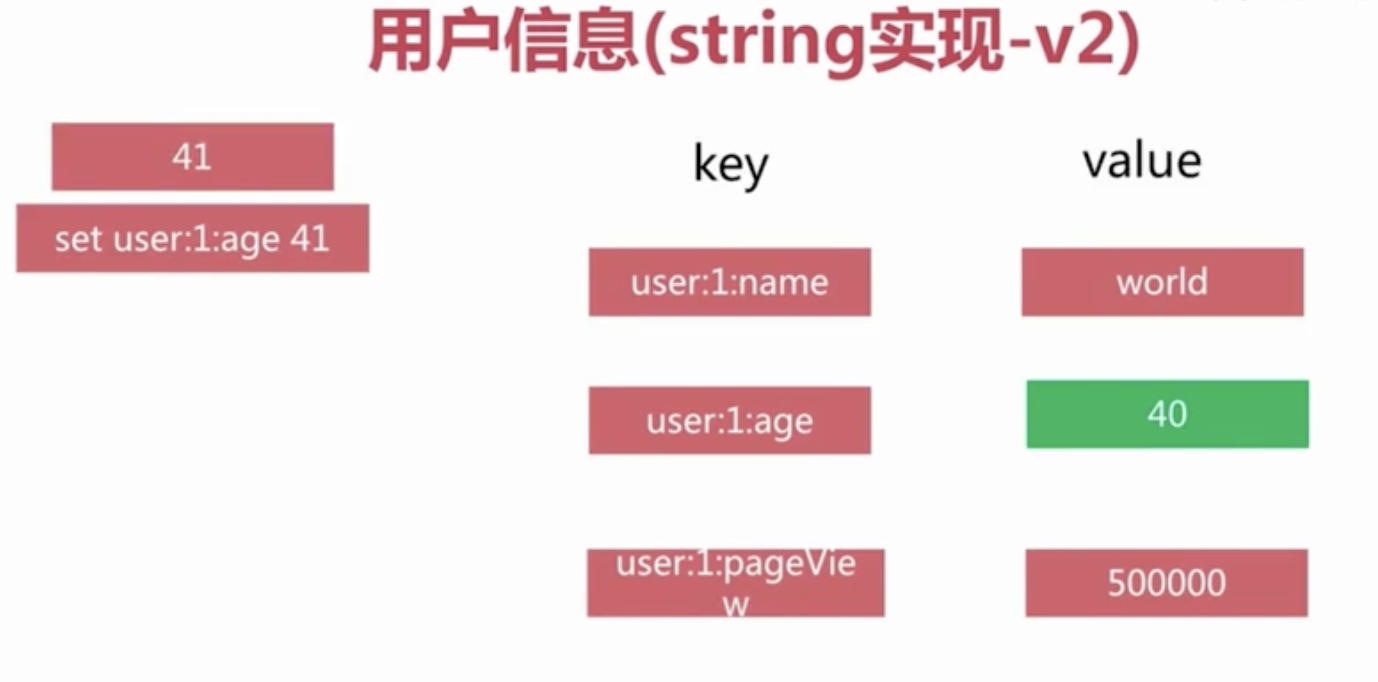
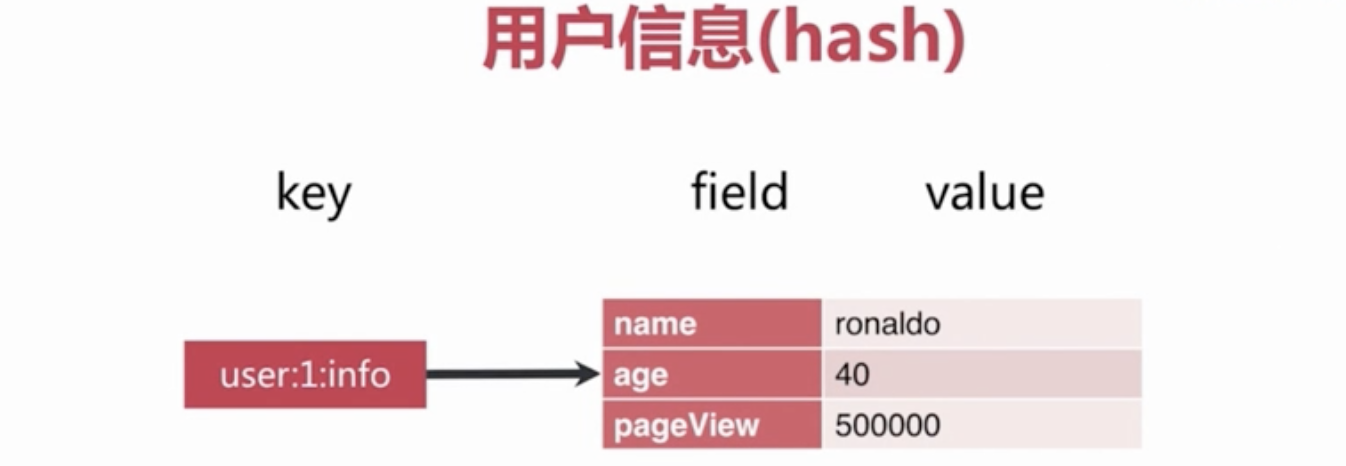
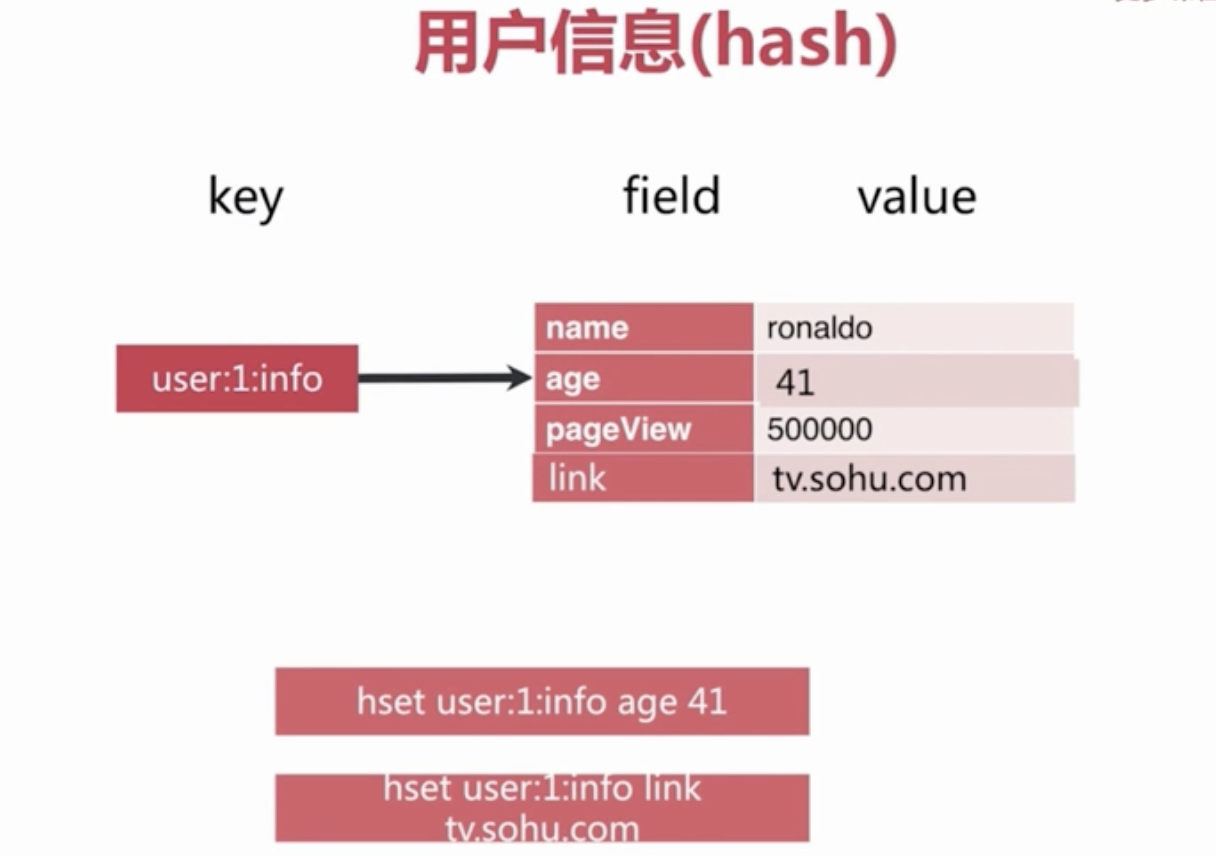


Redis Hashes 保存String域和String值之间的映射,所以它们是用来表示对象的绝佳数据类型(比如一个有着用户名,密码等属性的User对象):
hashtable或者 ziplist 实现
| `1` | `@cli` || `2` | `HMSET user:1000 username antirez password P1pp0 age 34` || `3` | `HGETALL user:1000` || `4` | `HSET user:1000 password 12345` || `5` | `HGETALL user:1000` |
一个有着少量数据域(这里的少量大概100上下)的hash,其存储方式占用很小的空间,所以在一个小的Redis实例中就可以存储上百万的这种对象。
虽然Hashes主要用于表示对象,他们可以存储很多的元素,所以你可以使用Hashes来做许多其他的工作。
Hash的最大长度是2^32 – 1个域值对(4294967295,一个Hash中可以有多达40多亿个域值对)
查看来获得更多信息,或者阅读一章
Sorted sets 类型(有序集合类型)
Redis有序集合类型与Redis的集合类型类似,是非重复的String元素的集合。不同之处在于,有序集合中的每个成员都关联一个Score,Score是在排序时候使用的,按照Score的值从小到大进行排序。集合中每个元素是唯一的,但Score有可能重复。
使用有序集合可以很高效的进行,添加,移除,更新元素的操作(时间消耗与元素个数的对数成比例)。由于元素在集合中的位置是有序的,使用get ranges by score或者by rank(位置)来顺序获取或者随机读取效率都很高。(本句不确定,未完全理解原文意思,是根据自己对Redis的浅显理解进行的翻译)访问有序集合中间部分的元素也非常快,所以可以把有序集合当做一个不允许重复元素的智能列表,你可以快速访问需要的一切:获取有序元素,快速存在测试,快速访问中间的元素等等。
简短来说,使用有序集合可以实现很多高性能的工作,这一点在其他数据库是很难实现的。
使用有序集合你可以:
在大型在线游戏中创建一个排行榜,每次有新的成绩提交,使用命令加入到有序集合中。可以使用命令轻松获得成绩名列前茅的玩家,你也可以使用根据一个用户名获得该用户的分数排名。把ZRANK 和 ZRANGE结合使用你可以获得与某个指定用户分数接近的其他用户。这些操作都很高效。
有序集合经常被用来索引存储在Redis中的数据。比如,如果你有很多用户,用Hash来表示,可以使用有序集合来为这些用户创建索引,使用年龄作为Score,使用用户的ID作为Value,这样的话使用 命令可以轻松和快速的获得某一年龄段的用户。
有序集合可能是Redis中最高级的数据类型了,所以请花一些时间查看一下 来获得更多信息,同时你可能也想阅读
Bitmaps and HyperLogLogs类型(位图类型和HyperLogLogs类型)
Redis 也支持位图类型和HyperLogLogs 类型,他们是在String基本类型基础上建立的类型,但有自己的语义。
0 Redis 数据结构简介
Redis是key-value的存储系统,其数据组成结构如下所示:
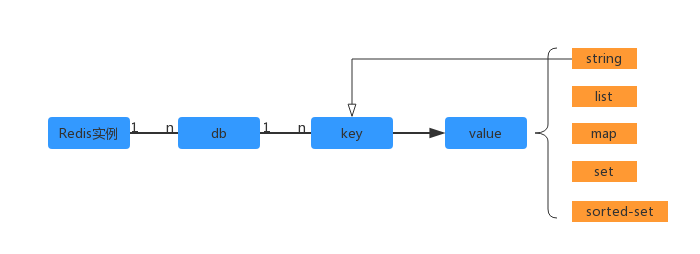
Redis 没有传统关系型数据库的Table 模型,schema 所对应的db仅以编号区分
同一个db 内,key 作为顶层模型,它的值是扁平化的。也就是说db 就是key的命名空间。key的定义通常以“:” 分隔,如:Article:Count:1。我们常用的Redis数据类型有:string、list、set、map、sorted-set。valueObject通用结构
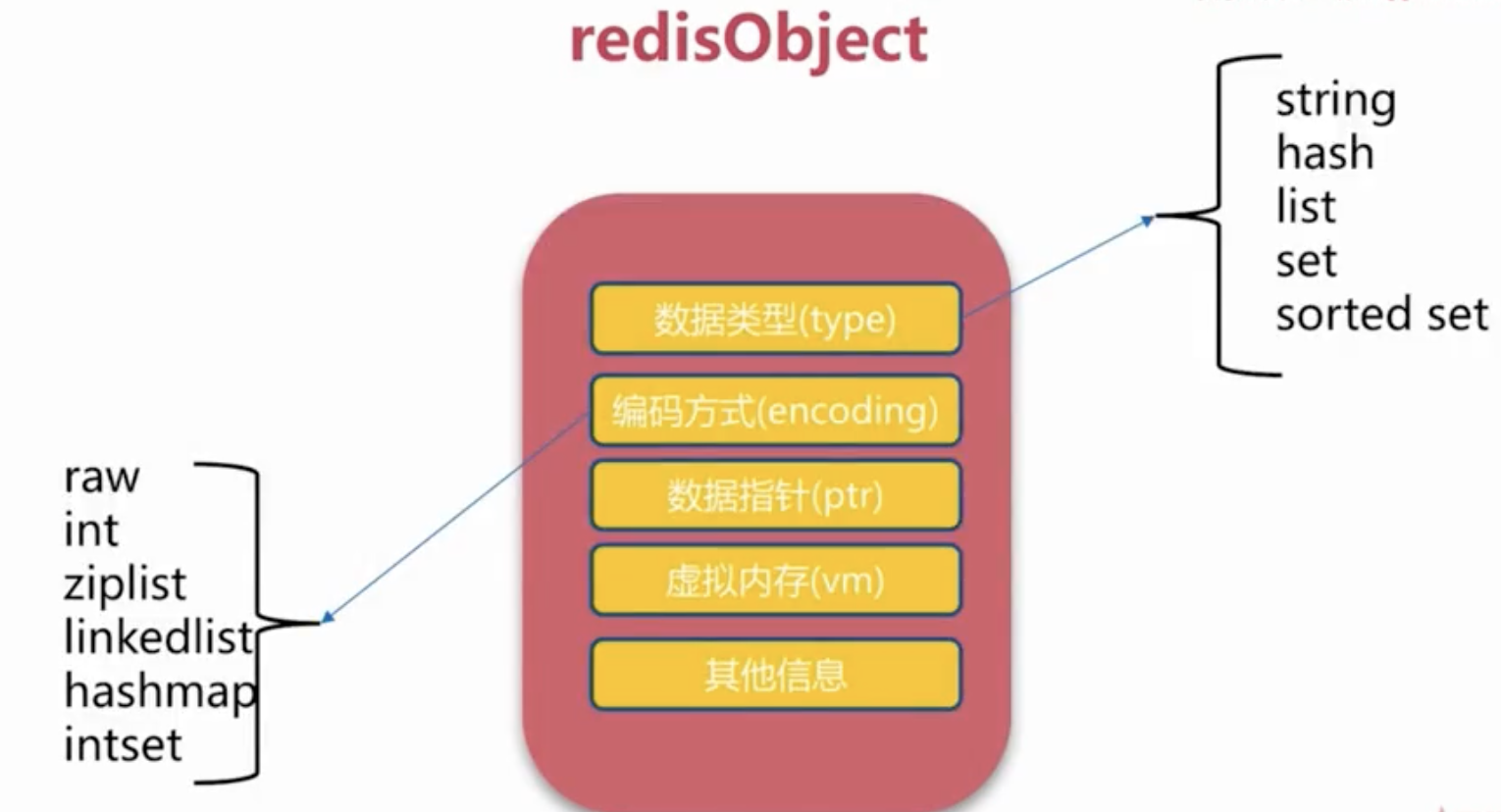
Redis中的所有value 都是以object 的形式存在的,其通用结构如下所示:
typedef struct redisObject { unsigned [type] 4; unsigned [encoding] 4; unsigned [lru] REDIS_LRU_BITS; int refcount; void *ptr;} robj; 
type 指的是前面提到的 string、list 等类型。
encoding 指的是这些结构化类型具体的实现方式,同一个类型可以有多种实现。如:string 可以用int 来实现,也可以使用char[] 来实现;list 可以用ziplist 或者链表来实现。
lru 表示本对象的空转时长,用于有限内存下长时间不访问的对象清理。
refcount 对象引用计数,用于GC。
ptr 指向以encoding 方式实现这个对象实际实现者的地址。如:string 对象对应的SDS地址(string的数据结构/简单动态字符串)。
string
Redis中的string 可以表示四很多语义,如:字节串(bits)、整数和浮点数。这三种类型,redis会根据具体的场景完成自动转换,并且根据需要选取底层的承载方式。例如整数可以由32-bit/64-bit、有符号/无符号承载,以适应不同场景对值域的要求。
基本操作
<caption style="box-sizing: border-box; padding-top: 8px; padding-bottom: 8px; color: rgb(119, 119, 119); text-align: left;">String类型的value基本操作</caption>
| 操作 | 描述 | |
|---|---|---|
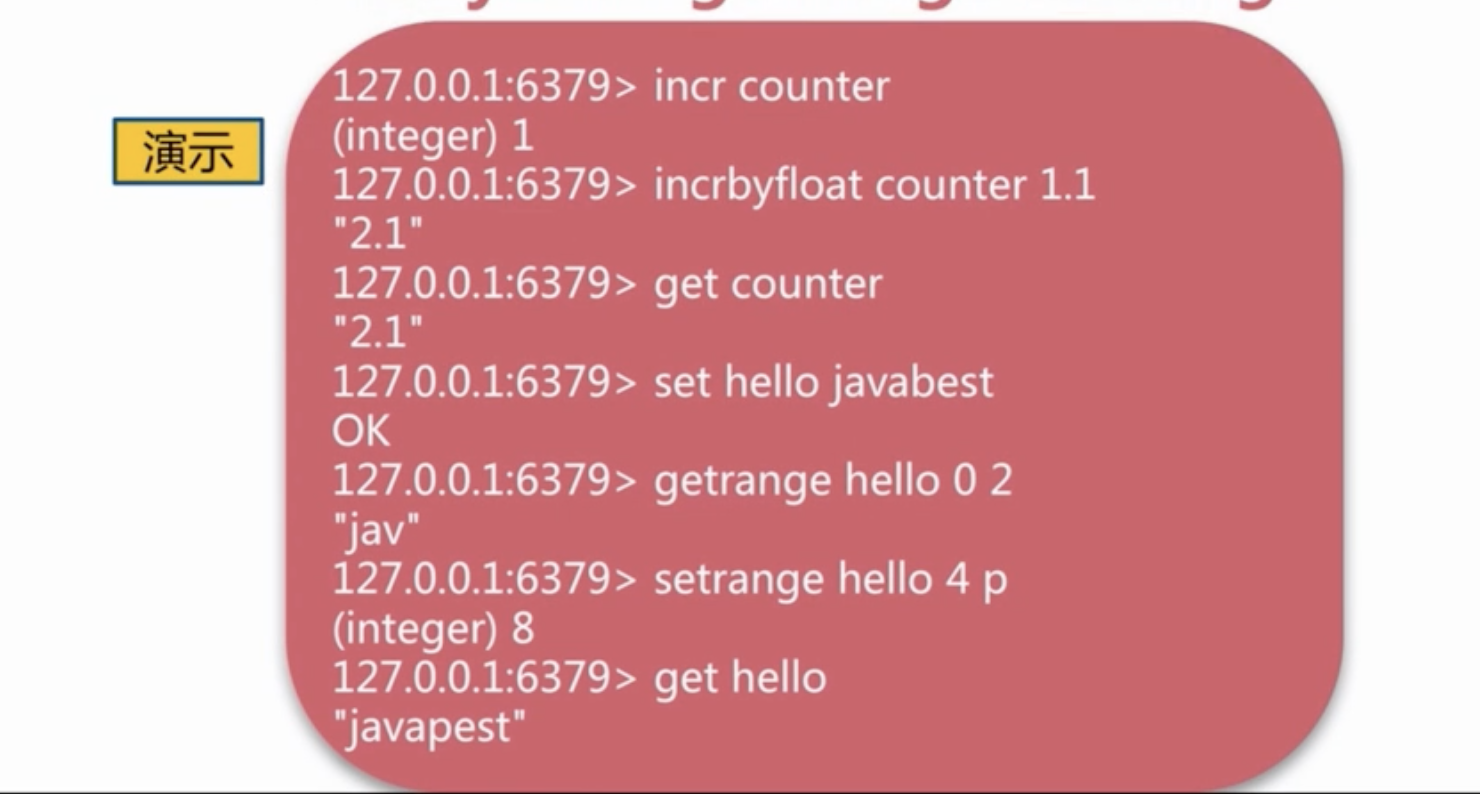
| 针对数字类型 | inc | 将指定key内容+1 |
| decr | 将指定key内容-1 | |
| incrby | 将指定key的内容增加指定值 | |
| decrby | 将指定key的内容减少给定值 | |
| incrbyfloat | 将指定key的内容减少给定的浮点值 | |
| 针对字节串类型 | append | 将指定字节串添加到key的value后 |
| getrange | 对字节串value做范围截取 | |
| setrange | 对字节串的指定start和end 做覆盖操作 | |
| strlen | 获取字节串value的长度 | |
| getbit | 对字节串value,获取指定偏移量上的bit(位) | |
| setbit | 将字节串value视为bit,并设置给定起始位置设置值 | |
| bitcount | 将字符串value视为bit,并统计1的数量 | |
| bitop | 对多个key的value做位运算,如:XOR、OR、AND、NOT |
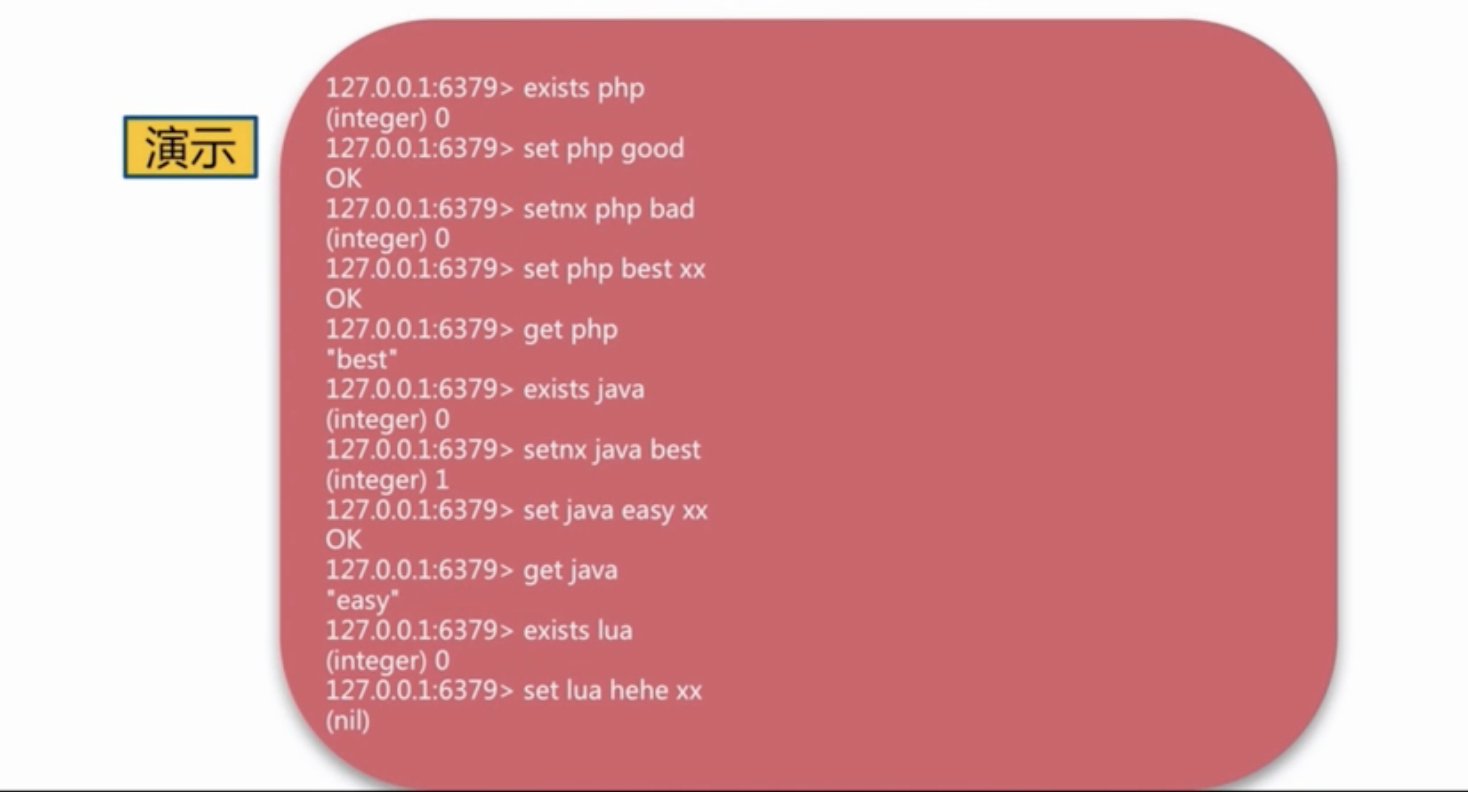
除此之外,string 类型的value还有一些CAS的原子操作,如:get、set、set value nx(如果不存在就设置)、set value xx(如果存在就设置)。
内存结构
在Redis内部,string的内部以 int、SDS(简单动态字符串 simple dynamic string)作为存储结构。int 用来存放整型数据;SDS 用来存放字节/字符和浮点型数据。
(1)SDS结构
typedef struct sdshdr { // buf中已经占用的字符长度 unsigned int len; // buf中剩余可用的字符长度 unsigned int free; // 数据空间 char buf[];} 其结构图如下所示:
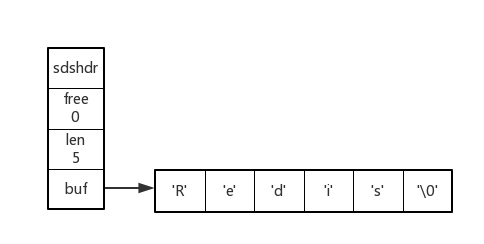
上面存储的内容为“Redis”,Redis采用类似C语言的存储方法,使用'\0'结尾(仅仅是定界符)。上面SDS的free 空间大小为0,当free > 0时,buf中的free 区域的引入提升了SDS对字符串的处理性能,可以减少处理过程中的内存申请和释放次数。
(2)buf 的扩容与缩容
当对SDS 进行操作时,如果超出了容量。SDS会对其进行扩容,触发条件如下:
A 字节串初始化时,buf的大小 = len + 1,即加上定界符'\0'刚好用完所有空间。
B 当对串的操作后小于1M时,扩容后的buf 大小 = 业务串预期长度 * 2 + 1,也就是扩大2倍。
C 对于大小 > 1M的长串,buf总是留出 1M的 free空间,即2倍扩容,但是free最大为 1M。
(3)字节串与字符串
SDS中存储的内容可以是ASCII 字符串,也可以是字节串。由于SDS通过len 字段来确定业务串的长度,因此业务串可以存储非文本内容。对于字符串的场景,buf[len] 作为业务串结尾的'\0' 又可以复用C的已有字符串函数。
(4)SDS编码的优化
value 在内存中有2个部分:redisObject和ptr 指向的字节串部分。在创建时,通常要分别为2个部分申请内存,但是对于小字节串,可以一次性申请。
使用场景
字符串类型的主要使用场景如下:缓存(缓存业务数据:如用户信息、商品信息等)、计数器(如网页浏览数)、分布式锁(如实现并发控制)等。
List
List就是列表对象,用于存储string序列。
基本操作
<caption style="box-sizing: border-box; padding-top: 8px; padding-bottom: 8px; color: rgb(119, 119, 119); text-align: left;">List类型的value基本操作</caption>
| 操作 | 描述 | |
|---|---|---|
| List 单key 操作 | rpush/lpush | 将指定string 添加到key 对应的列表中,lpush 表示头部插入,rpush 表示从尾部插入 |
| rpop/lpop | 将value 从列表中弹出(删除并返回已删除数据),lpop 表示从头部弹出;rpop 表示从尾部弹出 | |
| lindex | 获取列表中 index 位置上的元素的值 | |
| lrange | 获取列表中 start - end 的子列表,如 lrange key 0 9,即去除列表中前10个元素 | |
| ltrim | 删除列表中 start - end 的子列表内容 | |
| List 多key 操作 | blpop/brpop | 以阻塞的方式从多个 key 中弹出元素,并设置超时时间( 秒 ),返回目标 key 和 list 中的值,如:blpop key1 key2 60,依次从key1 key2 中查找 |
| blpoppush/brpoplush | blpoppush key1 key2 30 以阻塞的方式从 key1 的头部pop 元素,并添加到 key2 的尾部 |
内存数据结构
List 类型的 value对象,由 linkedlist 或者 ziplist 实现。当 List 元素个数少并且元素内容长度不大时,Redis 会采用ziplist 实现,否则使用linkedlist 实现。
linkedlist实现
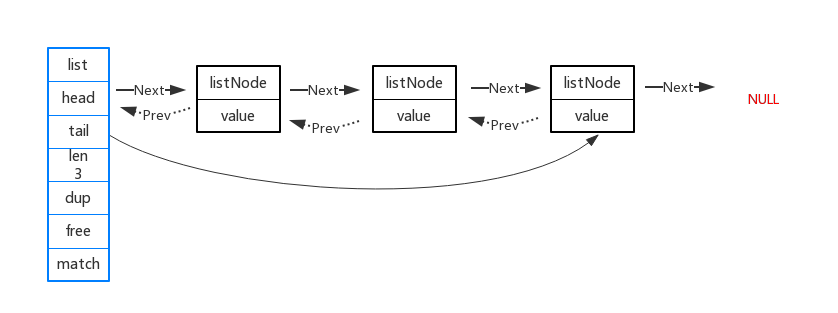
链表的代码结构如下所示:
typedef struct list { // 头结点 listNode *head; // 尾节点 listNode *tail; // 节点值复制函数 void *(*dup)(void * ptr); // 节点值释放函数 void *(*free)(void *ptr); // 节点值对比函数 int (*match)(void *ptr, void *key); // 链表长度 unsigned long len; } list;// Node节点结构typedef struct listNode { struct listNode *prev; struct listNode *next; void *value;} listNode; [图片上传中...(image-a621db-1534856351712-13)]
linkedlist 结构图如下所示:
ziplist实现
ziplist 是存储在连续内存中的,其组成结构图如下所示:

zlbytes:表示ziplist 的总长度。
zltail:指向最末元素。
zllen:表示元素的个数。
entry:为元素内容。
zlend:恒为0xFF,作为ziplist的定界符。
从上面的结构可以看出,对于linkedlist和 ziplist,它们的rpush、rpop、llen的时间复杂度都是O(1)。但是对于ziplist,lpush、lpop都会牵扯到所有数据的移动,时间复杂度为O(N)。但是由于List的元素少,体积小,这种情况还是可控的。
对于ziplist 的每个Entry 其结构如下所示:
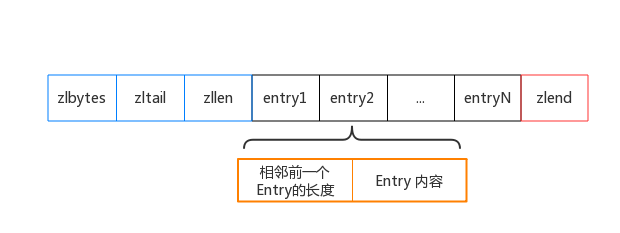
记录前一个相邻的Entry的长度,作用是方便进行双向遍历,类似于linkedlist 的prev 指针。ziplist是连续存储,指针由偏移量来承载。Redis中实现了2种方式的实现:当前邻 Entry的长度小于254 时,使用1字节来实现;否则使用5个字节。
这里面会有个问题,就是当前一个Entry的长度变化时,这时候有可能会造成后续的所有空间移动。当然这种情况发生的可能性比较小。
Entry内容本身是自描述的,意味着第二部分(Entry内容)包含了几个信息:Entry内容类型、长度和内容本身。而内容本身有包含:类型长度部分和内容本身部分。类型和长度同样采用变长编码:
00xxxxxx :string类型;长度小于64,0~63可由6位bit 表示,即xxxxxx表示长度。
01xxxxxx|yyyyyyyy : string类型;长度范围是[64, 16383],可由14位 bit 表示,即xxxxxxyyyyyyyy这14位表示长度。
10xxxxxx|yy..y(32个y) : string类型,长度大于16383.
1111xxxx :integer类型,integer本身内容存储在xxxx 中,只能是1~13之间取值。也就是说内容类型已经包含了内容本身。
11xxxxxx :其余的情况,Redis用1个字节的类型长度表示了integer的其他几种情况,如:int_32、int_24等。
由此可见,ziplist 的元素结构采用的是可变长的压缩方法,针对于较小的整数/字符串的压缩效果较好。
Map
Map类型的value 在Redis中又叫做 Hash。因为Redis本身是一个key - valueObject的结构,Hash类型的结构可以理解为subkey - subvalue。这里面的subkey - subvalue只能是:整型、浮点型或者字符串。
基本操作
<caption style="box-sizing: border-box; padding-top: 8px; padding-bottom: 8px; color: rgb(119, 119, 119); text-align: left;">Map类型的基本操作</caption>
| 操作 | 描述 | |
|---|---|---|
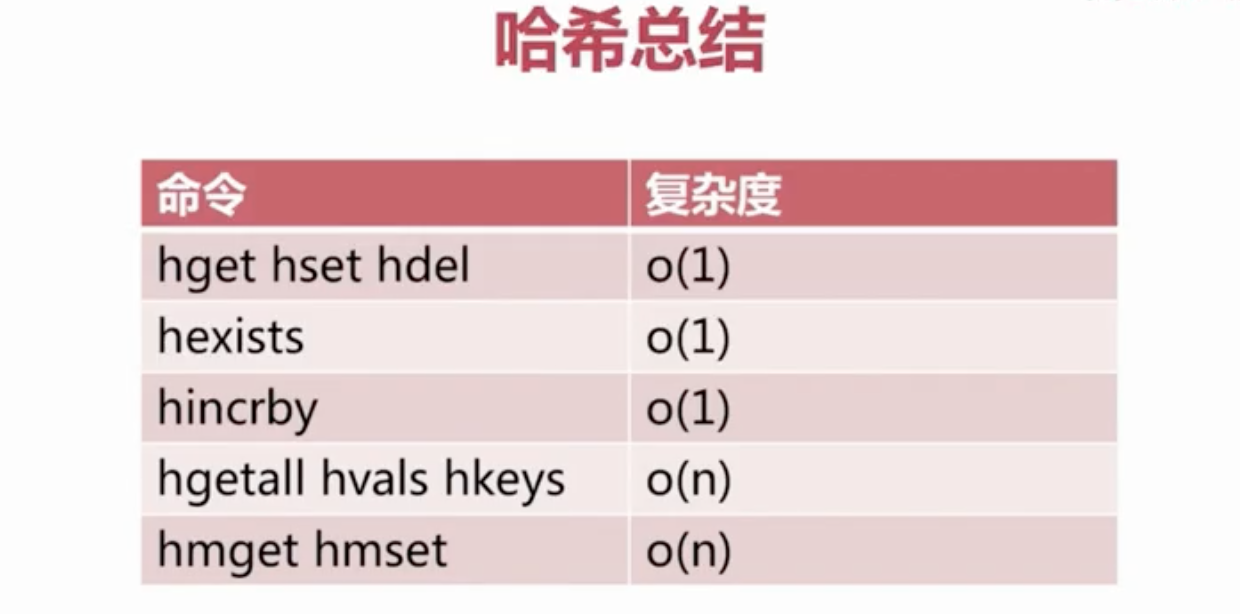
| Hash表的操作 | hget | hget key field,返回Hash表给定值域的值 |
| hset | hset key field value,将Hash表中key为field的值设置为value | |
| hmget | hmget key field [field ... ],返回Hash表中一个或多个field的值域 | |
| hmset | hmset key field value [field value ... ],同时将多个field - value设置到Hash表中 | |
| hgetall | hgetall key,返回Hash表中所有的filed - value对 | |
| hdel | hdel key field [field ... ],删除Hash表中一个或多个域 | |
| hkeys | hkeys key,返回Hash表中的所有field | |
| hvals | hvals key,返回Hash表中所有的values | |
| hlen | hlen key,获取Hash表域的数量 |
因为Map的value 可以表示整型和浮点型,因此Map也可以使用 hincrby 对某个field的value值做自增操作。
内存数据结构
Map可以由HashTable 和 ziplist 两种方式来承载。对于数据量较小的Map,使用ziplist 实现。
HashTable 实现
HashTable在Redis 中分为3 层,自底向上分别是:
dictEntry:管理一个field - value 对,同事保留同一桶中相邻元素的指针,以此维护Hash 桶中的内部链。
dictht:维护Hash表的所有桶链。
dict:当dictht需要扩容/缩容时,用户管理dictht的迁移。
dict是Hash表存储的顶层结构。其代码如下所示:
// 哈希表(字典)数据结构,Redis 的所有键值对都会存储在这里。其中包含两个哈希表。typedef struct dict { // 哈希表的类型,包括哈希函数,比较函数,键值的内存释放函数 dictType *type; // 存储一些额外的数据 void *privdata; // 两个哈希表 dictht ht[2]; // 哈希表重置下标,指定的是哈希数组的数组下标 int rehashidx; /* rehashing not in progress if rehashidx == -1 */ // 绑定到哈希表的迭代器个数 int iterators; /* number of iterators currently running */} dict; [图片上传中...(image-316142-1534856351712-9)]
Hash表的核心结构是dictht,它的table 字段维护着 Hash 桶,桶(bucket)是一个数组,数组的元素指向桶中的第一个元素(dictEntry)。
typedef struct dictht { //槽位数组 dictEntry **table; //槽位数组长度 unsigned long size; //用于计算索引的掩码 unsigned long sizemask; //真正存储的键值对数量 unsigned long used; } dictht; [图片上传中...(image-d5f793-1534856351712-8)]
其结构图如下所示:

从上图可以看出,Hash表使用的是 链地址法 解决Hash冲突的。当一个bucket 中的Entry 很多时,Hash表的插入性能会下降,此时就需要增加bucket的个数来减少Hash 冲突。
Hash表扩容
和大多数Hash表实现一样,Redis引入负载因子判定是否需要增加bucket个数,负载因子 = Hash表中已有元素 / bucket数量。扩容之后bucket的数量是原先的2倍。目前有2 个阀值:
小于1 时一定不扩容;
大于5 时一定扩容;
在1 ~ 5 之间时,Redis 如果没有进行bgsave/bdrewrite 操作时则会扩容。
当key - value 对减少时,低于0.1时会进行缩容。缩容之后,bucket的个数是原先的0.5倍。
ziplist 实现
这里面的ziplist 和List的ziplist实现类似,都是通过Entry 存放element。和List不同的是,Map对应的ziplist 的Entry 个数总是2的整数倍,第奇数个Entry 存放key,下一个相邻的Entry存放value。
ziplist承载时,Map的大多数操作不再是O(1)了,而是由Hash表遍历,变成了链表的遍历,复杂度变为O(N)。由于Map相对较小时采用ziplist,采用Hash表时计算hash值的开销较大,因此综合起来ziplist的性能相对好一些。
Set
Set类似List,但是它是一个无序集合,包含的元素不重复。
基本操作
<caption style="box-sizing: border-box; padding-top: 8px; padding-bottom: 8px; color: rgb(119, 119, 119); text-align: left;">Set 基本操作</caption>
| 操作 | 描述 | |
|---|---|---|
| Set 基本操作 | sadd | sadd key member [member ... ],将一个或多个member 放入集合中 |
| srem | srem key member [member ... ],移除一个或多个member | |
| sismember | sismember key member,检查member是否在集合中 | |
| scard | scard key,返回集合中元素的个数 | |
| smembers | smembers key,返回集合中所有的元素 | |
| srandmember | srandmember key [count],随机返回1个(默认)或多个成员 | |
| Set 复合操作 | sinter | sinter key [key...],返回多个集合的交集 |
| sunion | sunion key [key ...],返回多个集合的并集 | |
| sdiff | sdiff key [key ...],返回第一个集合与后面所有集合的差集 | |
| Set 复合存储 | sinterstore | sinterstore destination key [key ...],与sinter类似,不过将结果集存放到destination集合中 |
| sunionstore | sunionstore destination key [key ...],与sunion类似,将结果集存放到destination中 | |
| sdiffstore | sdiffstore destination key [key...],与sdiff类似,将结果集存放到destination中 |
内存数据结构
Set在Redis中以intset 或 hashtable来存储。Hashtable前面已经介绍过了,对于Set,HashTable的value永远为NULL。当Set中只包含整型数据时,采用intset作为实现。
intset
intset的核心元素是一个字节数组,其中从小到大有序的存放着set的元素,其代码结构如下所示:
typedef struct intset { // 编码方式 uint32_t enconding; // 集合包含的元素数量 uint32_t length; // 保存元素的数组 int8_t contents[];} intset; [图片上传中...(image-bbb527-1534856351711-6)]
其结构图如下所示:
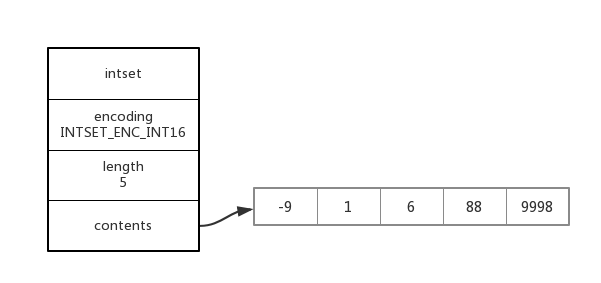
因为元素有序排列,所以SET的获取操作采用二分查找的方式,复杂度为O(log(N))。
进行插入操作时,首先通过二分查找到要插入的位置,再对元素进行扩容。然后将插入位置之后的所有元素向后移动一个位置,最后插入元素。时间复杂度为O(N)。
为了使二分查找的速度足够快,存储在content 中的元素是定长的。
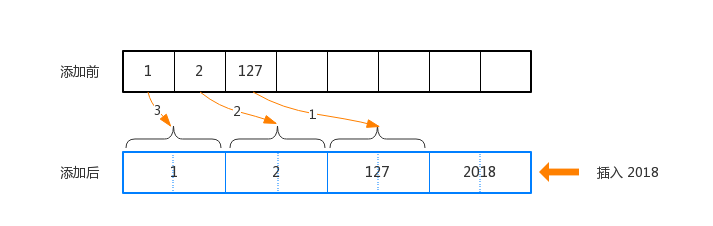
从上图中可以看出,当插入2018 时,所有的元素向后移动,并且不会发生覆盖的情况。并且当Set 中存放的整型元素集中在小整数范围[-128, 127]内时,可以大大的节省内存空间。这里面需要注意的是:IntSet支持升级,但是不支持降级。
Sorted-Set
Sorted-Set是Redis特有的数据,类似于Map的key-value对,但是它是有序的。
key :key-value对中的键,在一个Sorted-Set中不重复。
value : 是一个浮点数,称为 score。
有序 :内部按照score 从小到大的顺序排列。
基本操作
由于Sorted-Set 本身包含排序信息,在普通Set 的基础上,Sorted-Set 新增了一系列和排序相关的操作:
<caption style="box-sizing: border-box; padding-top: 8px; padding-bottom: 8px; color: rgb(119, 119, 119); text-align: left;">Sorted-Set的基本操作</caption>
| 操作 | | 描述 | | --- | --- | --- | |Sorted-Set 特有操作
(与Set相比)
| zrank |
zrank key member, 返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递增(从小到大)顺序排列。
|
| zrange |zrange key start stop [WITHSCORES],返回有序集 key 中,指定区间内的成员。
|
| zrangebyscore |zrangebyscore key min max [WITHSCORES] [LIMIT offset count], 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
|
| zscore |zscore key member,返回有序集 key 中,成员 member 的 score 值。
|
| zincrby |zincrby key increment member,为有序集 key 的成员 member 的 score 值加上增量 increment 。
|
内部数据结构
Sorted-Set类型的valueObject 内部由ziplist或者 skiplist+hashtable来实现。
作为ziplist的实现方式和Map类似。由于Sorted-Set包含了Score的排序信息,ziplist内部的key-value元素对的排序方式也是按照Score递增排序的,意味着每次插入数据都要移动之后的数据。因此ziplist适用于元素个数不多,元素内容不大的场景。
对于更通用的场景,Sorted-Set使用sliplist来实现。
skiplist
和通用的跳表不同的是,Redis为每个level 对象增加了span 字段,表示该level 指向的forward节点和当前节点的距离,使得getByRank类的操作效率提升。skiplist的代码结构如下:
typedef struct zskiplist { //表头节点和表尾节点 structz skiplistNode *header,*tail; //表中节点数量 unsigned long length; //表中层数最大的节点的层数 int level;} zskiplist; [图片上传中...(image-3da94a-1534856351711-3)]
skiplistNode的代码结构如下所示:
typedef struct zskiplistNode { // 层 struct zskiplistLevel{ struct zskiplistNode *forward; // 前进指针 unsigned int span; // 跨度 } level[]; // 后退指针 struct zskiplistNode *backward; // 分值 double score; // 成员对象 robj *obj;} [图片上传中...(image-97a0c2-1534856351711-2)]
skiplist的结构示意图如下所示:
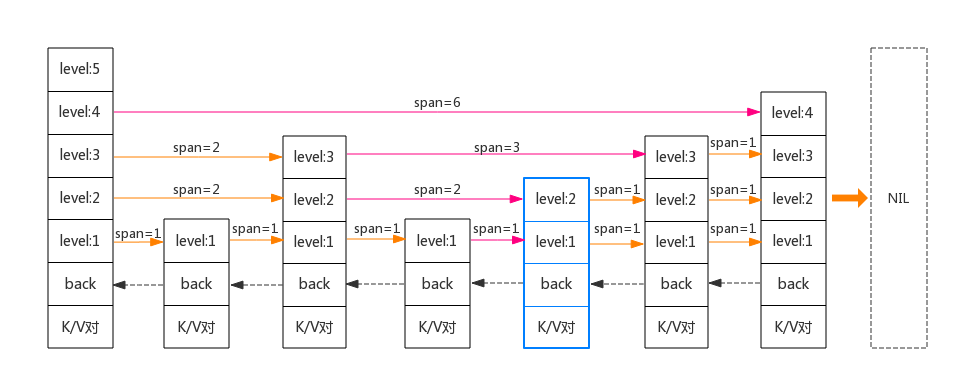
从上图可以看出,每次向skiplist 中新增或者删除一个节点时,需要同时修改图标中红色的箭头,修改其forward和span的值。可以看出,需要修改的箭头和对skip进行查找操作遍历并废弃过的路径是吻合的。对于span的修改仅仅是+1或者-1 。skiplist 的查找复杂度平均是 O(Log(N)),因此add / remove的复杂度也是O(Log(N))。因此Redis中新增的span 提升了获取rank(排序)操作的性能,仅需对遍历路径相加即可(矢量相加)。
还有一点需要注意的是,每个skiplist的节点level 大小都是随机生成的(1-32之间)。
hashtable
skiplist 是zset 实现顺序相关操作比较高效的数据结构,但是对于简单的zscore操作效率并不高。Redis在实现时,同时使用了Hashtable和skiplist,代码结构如下:
typedef struct zset { dict *dict; zskiplist *zsl;} zset; [图片上传中...(image-57708a-1534856351711-0)]
Hash表的存在使得Sorted-Set中的Map相关操作复杂度由O(N)变为O(1)。
转载地址:http://pwlgo.baihongyu.com/